Grain - Map user journeys in real time and tune with remote config
GrainQL 是一个开源的数据质量平台,旨在帮助企业识别、监控并解决现代数据栈中的数据质量问题。它提供灵活的规则引擎、广泛的数据源连接器、实时监控与警报,并支持数据血缘分析,以提升数据可靠性和信任度,适用于数据迁移、合规性、BI和机器学习模型训练等场景。
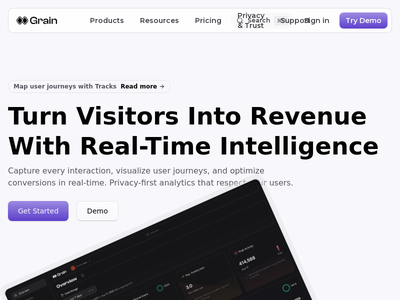
GrainQL 分析
从产品经理角度:
1. 解决的核心问题与价值主张: * 问题痛点: 现有的数据资产(数据库、数据湖、SaaS应用等)碎片化、缺乏统一语义解释,导致数据分析复杂、效率低下。业务用户无法直接获取信息,依赖数据团队,形成瓶颈。同时,大型语言模型(LLMs)在处理企业私有数据时,缺乏上下文和语义理解,容易“幻觉”,无法准确生成SQL或提供可靠洞察。 * 价值主张: GrainQL 提供一个“AI-Native 语义层”,通过构建企业知识图谱,将复杂、异构的数据转化为统一、可理解的业务概念。它承诺让业务用户通过自然语言直接查询数据,并为LLMs提供准确、可靠的结构化上下文,从而生成高质量的SQL,避免幻觉,实现真正的“数据自由”和“AI赋能分析”。
2. 目标用户群体: * 数据工程师/数据架构师: 负责构建和维护语义层,希望简化数据建模、元数据管理和数据治理的工作。 * 数据分析师/科学家: 希望快速、准确地获取业务数据,减少数据准备时间,专注于洞察发现。 * 业务用户: 非技术背景,希望通过自然语言直接查询数据,自助获取业务洞察。 * AI/LLM开发者: 寻求为LLMs提供结构化、高质量的领域知识和数据上下文,提升RAG(检索增强生成)和LLM应用的效果。
3. 核心功能与技术亮点: * AI驱动的知识图谱构建: 这是关键创新点。如何自动化或半自动化地从现有数据源中提取实体、关系和属性,并构建成可用的知识图谱,将是决定其易用性和准确性的核心。 * 统一语义层: 抽象底层数据复杂性,提供一致的业务视图。 * 自然语言到SQL转换(NL2SQL): 允许用户通过日常语言提问,系统自动生成执行SQL,降低数据查询门槛。 * LLM增强的语义理解: 为LLMs提供可靠的数据上下文,确保其生成的数据洞察或SQL语句是准确且符合业务逻辑的。 * 多数据源连接: 支持连接各种企业数据源是基础。 * 数据治理与安全: 作为一个企业级产品,权限管理、数据质量监控、审计等功能必不可少(官网未详述,但PM会重点关注)。
4. 用户体验与产品策略: * 上手难度: 构建知识图谱本身是复杂任务。产品需提供直观的UI/UX,引导用户逐步定义实体、关系和业务术语,降低初始配置的门槛。AI的介入应体现在辅助而非完全替代人工。 * 准确性与可信度: NL2SQL和AI生成的SQL的准确性是生命线。产品需要提供机制让用户验证、纠正和反馈,以持续优化模型。解释性(为什么生成这个SQL)也很重要。 * 集成能力: 需与现有数据栈(BI工具、数据仓库、数据湖、ETL/ELT工具)无缝集成,降低用户迁移成本。 * 迭代路径: 初期可能专注于核心的知识图谱构建和NL2SQL。未来可以扩展到更高级的分析、数据质量管理、自动化报告生成等。
5. 潜在挑战与风险: * “垃圾进,垃圾出” (GIGO): 如果底层数据质量差或业务逻辑混乱,AI也难以构建出高质量的知识图谱。产品需面对如何处理脏数据的问题。 * AI的准确性与偏见: NL2SQL的鲁棒性在复杂查询和模糊语义下仍是挑战。如何处理歧义、提高泛化能力是核心。 * 企业采纳周期: 改变企业数据基础设施需要较长的销售和实施周期,特别是对于核心的语义层产品。 * 竞争: 现有数据目录、BI工具(如Looker的LookML)、Data Mesh相关产品、以及其他语义层创业公司(如Atlan, Stemma, Cube.dev)都是直接或间接的竞争对手。如何体现其AI-native的真正差异化价值。
从投资人角度:
1. 市场机遇与规模 (TAM): * 巨大痛点: 数据驱动决策是企业共识,但数据获取和理解仍是巨大瓶颈。LLM的兴起进一步放大了对结构化、可信数据上下文的需求。 * 市场规模: 涉及数据治理、BI、数据集成、分析工具等多个市场,是一个万亿级的市场。语义层作为数据栈的核心枢纽,潜力巨大。 * 趋势: AI/LLM浪潮提供巨大助推力,企业对AI应用落地,尤其是私有数据RAG的需求迫切。语义层是LLM安全、准确理解企业数据并进行交互的关键基础设施。
2. 产品与技术护城河: * 技术领先性: “AI-Native 语义层”和“AI驱动的知识图谱构建”是亮点。如果能在自动化图谱构建、NL2SQL的准确性、以及LLM与语义层的深度融合上形成核心技术优势,将构成强大的护城河。 * 数据飞轮效应: 随着更多用户使用和反馈,AI模型可以持续学习和优化,提高语义理解和SQL生成能力,形成数据驱动的竞争优势。 * 高粘性: 语义层作为数据栈的核心,一旦企业采纳并构建起知识图谱,迁移成本极高,用户粘性强。
3. 团队与执行力: * 核心能力: 需要同时具备AI/ML、图数据库、大数据、企业级SaaS产品开发和销售的复合型团队。 * 行业经验: 团队成员在相关领域(如数据平台、BI、AI研究)的背景和经验至关重要。
4. 市场进入策略 (GTM) 与竞争格局: * 早期客户: 优先选择数据成熟度高、数据量大、业务复杂、对LLM应用有迫切需求的大型企业或技术型公司。 * 销售模式: likely是高触碰的B2B企业级销售模式,需要强大的销售和售前团队。 * 竞争: * 传统BI/数据目录厂商: 如Looker、Alation、Collibra等,他们也在加强语义层能力。 * Data Mesh/Data Fabric解决方案: 提供数据治理和集成,但通常不深入语义层。 * 新兴语义层厂商: Cube.dev、Atlan、Stemma等,各有侧重。 * 云服务提供商: AWS、Azure、GCP在构建自己的数据工具生态。 * 差异化: GrainQL需要清晰地阐明其在“AI-native”和“知识图谱驱动LLM”方面的独特优势,而不是简单地做另一个语义层。
5. 商业模式与财务预测: * 定价模型: 可能是基于数据量、用户数、功能模块或API调用量等组合。作为核心基础设施,通常是高价值、高ARPU(平均每用户收入)的订阅模式。 * 收入增长: 市场需求巨大,早期客户验证成功后,有望实现快速ARR增长。 * 风险: * 技术实现难度: 构建准确、可扩展的AI驱动知识图谱和NL2SQL是极高难度的工程和AI挑战。 * 客户教育成本: 语义层概念相对复杂,需要投入教育市场。 * 销售周期长: 企业级SaaS销售周期长,CAC(客户获取成本)可能较高。 * 合规性与安全性: 处理企业敏感数据,必须有强大的安全和合规能力。
投资总结: GrainQL 切入了一个巨大且日益增长的市场痛点,其“AI-Native 知识图谱语义层”的定位具有前瞻性和颠覆潜力。如果团队能够成功地将AI技术转化为高度准确、易于使用的产品,并有效应对企业级销售和技术挑战,那么它有可能成为数据领域新一代的核心基础设施。但技术执行的复杂性、市场教育以及与现有巨头的竞争是其面临的主要风险。