Spiderseek - Grow & Monitor Your AI Search Traffic
Spiderseek 是一个免费的开源网络资产搜索引擎,旨在帮助安全研究人员、渗透测试人员和安全专业人士快速发现、分析和管理网络资产。它提供海量数据、快速查询、高级搜索功能以及API支持,是进行安全研究、漏洞挖掘和信息收集的有力工具。
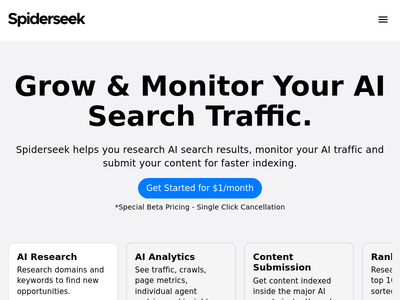
产品经理 (Product Manager) 角度
1. 核心价值与用户痛点
- 核心价值主张 (Value Proposition): "Web scraping without coding" (无需编程的网络数据抓取)。这清晰地定位了其目标用户群体——那些需要网络数据但缺乏编程技能,或不希望投入编程资源的用户。
- 解决的痛点 (Pain Points Solved):
- 技术门槛高: 传统爬虫开发需要Python/JS等编程知识,SpiderSeek通过可视化界面解决了这一痛点。
- 维护成本高: 网站结构变化、IP封锁、代理管理等问题常导致爬虫失效,SpiderSeek提供云端解决方案,旨在降低用户的维护负担。
- 开发周期长: 快速获取特定数据时,从零开始开发爬虫耗时耗力,SpiderSeek承诺快速部署。
- 可扩展性与稳定性: 个人或小型团队难以搭建高并发、高稳定的爬虫系统,平台化的服务能提供更好的保障。
2. 产品特点与优势
- 可视化操作 (Visual Interface): 这是无代码工具的基石。通过点击、选择等方式定义抓取规则,大大降低了学习曲线。
- 云端运行与调度 (Cloud-Based & Scheduling): 用户无需部署任何软件,任务在云端执行,并可设置定时抓取,实现自动化。这解决了本地机器限制和能源消耗问题。
- 数据导出格式多样 (Diverse Export Formats): 支持CSV、JSON等常见格式,方便用户集成到其他工具或数据库。
- 反爬虫机制处理 (Anti-Scraping Handling): 网站宣传提到了“Scalable & Reliable”,这通常意味着平台具备IP轮换、User-Agent管理、验证码处理等反爬虫能力,这是这类工具的核心竞争力。
- 简洁的用户界面 (Clean UI): 网站设计简洁明了,首页直接突出核心价值和“How it Works”视频,有助于新用户快速理解。
3. 用户体验 (UX) 评估与建议
- 优点:
- 上手引导: “How it Works”视频是很好的引导工具,直观展示了产品操作流程。
- 页面简洁: 避免了信息过载,核心功能突出。
- CTA清晰: “Sign up for free”等按钮明确,引导用户注册体验。
- 改进建议:
- 无代码编辑器预览: 在不注册的情况下,能否提供一个交互式DEMO或模拟器,让潜在用户直接体验可视化编辑器的强大(或局限性),这将极大增强信任和吸引力。
- 用例与模板: 提供预设的常见网站抓取模板(如Amazon产品信息、LinkedIn职位信息、新闻网站文章等),能帮助用户快速入门并看到产品的实际应用价值。
- 博客/教程: 目前网站的Blog页面是空白的。对于无代码工具,高质量的教程、最佳实践、行业应用案例(Case Study)至关重要,能有效提升SEO、用户留存和品牌影响力。
- 社区/支持: 建立用户社区、FAQ或更详细的帮助文档,提供即时支持,解决用户在使用过程中遇到的各种问题。
- 错误处理与反馈: 实际使用中,爬虫失败是常态。产品应提供清晰的失败原因分析、日志和建议,帮助用户调整规则。
4. 市场定位与竞争
- 市场定位: 主要瞄准对技术栈要求不高、追求效率和成本效益的个人用户、小型企业、市场营销人员、数据分析师和研究人员。
- 竞争环境:
- 直接竞品: Octoparse、Import.io、Web Scraper.io (浏览器插件)、Apify (更偏开发者)、Bright Data (更偏基础设施) 等。
- 间接竞品: 自建爬虫团队/外包服务。
- 差异化: SpiderSeek的网站简洁性暗示其可能在“极致简单易用”和“合理价格”上寻求差异化。然而,在功能上,它需要证明其在处理复杂网站(如JavaScript渲染、登录验证)方面与竞品的能力不相上下甚至更优。
5. 发展与迭代建议
- 功能深度拓展:
- 支持更复杂的交互(点击、滚动、填写表单)。
- 增加数据清洗、转换功能(如日期格式化、文本提取正则)。
- 提供API接口,方便高级用户集成到自有系统中。
- Webhook集成,实时推送抓取结果。
- 生态系统建设:
- 与其他数据分析工具(如Google Sheets、BI工具)进行更深度的集成。
- 开放平台,允许用户分享和售卖自定义爬虫模板。
- 市场拓展:
- 针对特定行业(如电商、房地产、招聘、新闻媒体)提供定制化解决方案或模板。
- 多语言支持,进入国际市场。
- 用户教育与内容营销: 填充博客,发布行业报告、数据分析案例、产品教程。
投资人 (Investor) 角度
1. 市场潜力与规模 (Market Potential & Size)
- 市场刚需: 随着数据驱动决策成为常态,对高质量、实时网络数据的需求爆炸式增长。无论大小企业、个人研究者,都渴求获取公开网络信息。
- 无代码/低代码趋势: 这是一个巨大的市场趋势,它正在“民主化”技术,使得非技术人员也能利用复杂工具。SpiderSeek正处在这个风口。
- 潜在市场规模 (TAM): 涵盖了全球所有需要网络数据的企业和个人。从市场营销、竞争情报、价格监控、新闻聚合、招聘、学术研究到房地产分析,应用场景极广。
- 可服务市场规模 (SAM): 聚焦于无代码/低代码解决方案,该细分市场同样巨大且增速快。
2. 商业模式与盈利能力 (Business Model & Profitability)
- SaaS订阅模式: 提供按月/年付费的订阅服务,是典型的SaaS模式。这种模式具有可预测的经常性收入(MRR/ARR),毛利率通常较高,且用户生命周期价值(LTV)可观。
- 分级定价策略 (Tiered Pricing): 根据抓取页数、项目数量、并发任务、数据导出量等维度设置不同等级的套餐,能够满足不同规模和需求的用户,实现收入最大化。免费试用是有效的用户获取手段。
- 规模效应: 作为云服务,一旦基础设施搭建完毕,用户增长的边际成本相对较低,有望实现高盈利能力。
- 关键指标: 投资者会关注的关键指标包括:
- 月/年度经常性收入 (MRR/ARR)
- 客户获取成本 (CAC)
- 客户生命周期价值 (LTV)
- 客户流失率 (Churn Rate)
- 毛利率 (Gross Margin)
3. 竞争格局与护城河 (Competitive Landscape & Moats)
- 竞争激烈: Web scraping领域是红海市场,国内外存在众多成熟玩家。
- 潜在护城河 (Potential Moats):
- 用户体验与易用性 (UX/Simplicity): 如果能在无代码爬虫领域做到极致简单和高效,这将是一个重要的差异化优势。
- 技术领先性 (Proprietary Technology): 在处理复杂网站(如JS渲染、验证码、高级反爬)时的稳定性、准确性和速度,以及IP管理、分布式架构等是核心技术护城河。
- 网络效应/社区 (Network Effects/Community): 如果能建立起活跃的用户社区,分享模板、解决问题,将形成强大的生态系统。
- 数据飞轮 (Data Flywheel): 如果平台能通过用户行为数据优化爬取策略,或提供增值数据服务,则能形成数据驱动的飞轮效应。
- 品牌与早期市场份额 (Brand & Early Market Share): 快速抢占市场,建立品牌认知度。
- 当前挑战: 仅从网站看,其护城河尚不明显。需要强大的执行力在某个细分市场或用户体验上形成突破。
4. 团队与执行力 (Team & Execution)
- 重要性: 团队的背景、技术实力、市场运营能力和融资能力是决定项目成败的关键。
- 需要关注:
- 团队在Web Scraping技术、SaaS产品开发、产品设计和市场营销方面的经验。
- 团队对市场和用户需求的理解。
- 团队的迭代速度和适应能力。
5. 风险与挑战 (Risks & Challenges)
- 法律与合规风险 (Legal & Compliance): 网络爬虫的合法性一直备受争议,受网站ToS、数据隐私法规(如GDPR、CCPA)影响。平台需要有应对策略。
- 技术挑战: 网站反爬机制日益复杂;维护爬虫的稳定性(网站结构频繁变动)是长期挑战。
- 市场竞争: 面对众多竞争者,如何持续创新、保持差异化并有效获取用户?
- 客户流失: 如果用户需求升级或遇到更复杂的网站,可能转向更专业的工具或自建方案。
- 道德伦理: 数据抓取可能引发的道德争议。
6. 投资吸引力与估值潜力 (Investment Appeal & Valuation Potential)
- 吸引力:
- 身处快速增长的“数据+无代码”大赛道。
- SaaS商业模式具有高LTV、高毛利的潜力。
- 目标用户群体庞大。
- 估值潜力:
- 取决于其用户增长率、营收规模、CAC/LTV比率、毛利率、市场份额以及护城河的构建情况。
- 早期项目估值会主要看团队、市场潜力和产品MVP的验证。如果能快速获得早期用户和收入,并展示出良好的增长势头,则具备较高估值潜力。
- 尽职调查重点: 投资者会深入调研其技术栈、用户数据(活跃用户、付费用户、ARPU、流失率)、财务数据、市场策略以及法律合规性。
总结: SpiderSeek的定位清晰,抓住了市场痛点和无代码趋势。作为产品经理,我认为其在用户体验优化、功能深度和内容营销上有很大的提升空间。作为投资人,我对这个赛道充满兴趣,但会更关注其核心技术壁垒、用户增长数据、留存表现以及团队在激烈竞争中突围的能力。